STEP ONE: SURVEYS
These surveys have been through the ringer. It was a difficult task to get responses on them for multiple reasons. In the end it took over a month to get responses on the surveys. The purpose of the survey was to have a specific audience based on the greater research question. The final goal was to ask these specific groups questions to gain their insight on progress that the research teams have made so far. The survey questions were about Indigenous knowledge and where this wicked problem currently places within the multitude of wicked problems present at MOBOT.
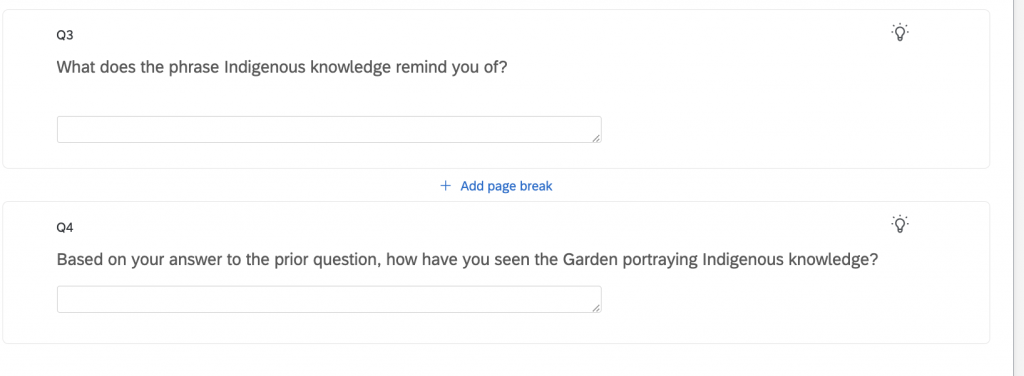
One of the questions asked was “Based on your answer to the prior question, how have you seen the Garden portraying Indigenous knowledge?” For some context, the previous question pertained to what the phrase Indigenous knowledge meant to them. One of the responses to this question was moving. The response was “We could be doing more. I actually have a hard time thinking of examples when the Garden has handled this topic well. I can actually think of more examples of times the Garden missed opportunities to present local knowledge and didn’t promote them very well through social media and local TV/radio spots (Kwanzaa, Indigenous Peoples Day, Japanese Festival).” This response shows one of the main HUGE aspects about a wicked problem that takes forever to be known. What I am speaking of is ACKNOWLEDGING THE PROBLEM!! Based on the other responses, no one else acknowledged or shed light on the fact that more needs to be done.G
STEP TWO: FOCUS GROUPS
The next step that was supposed to happen was that based on the survey responses, we were supposed to take a deeper dive into the responses that we received. We were then supposed to build a different set of questions to help us understand why one group of answers on the survey were what they were. In the end, what ended up ACTUALLY happening was the survey responses were not received until a month after they were needed so the research teams just had to take the deep dive without the background information, and actually just based on what we each thought would be a good idea to build on for the in person focus groups/interviews.
The focus groups happened on April 3, and they went relatively smoothly in my opinion. All research groups were set up in an auditorium room and the staff that could make it were there. To be fair, most of the opinions that were given that day were quite insightful, however, some of the responses felt roboticized. For example, when our research group met with one of the researchers, the responses were good they really were, but when they spoke it almost felt like they were showing the best sides of MOBOT and would never speak bad on the Garden.
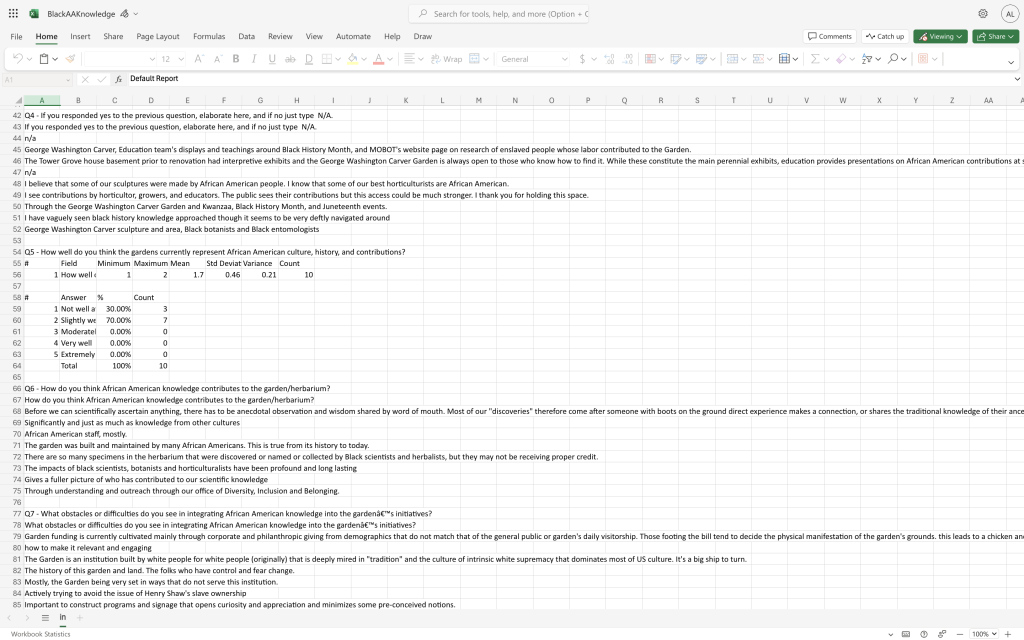
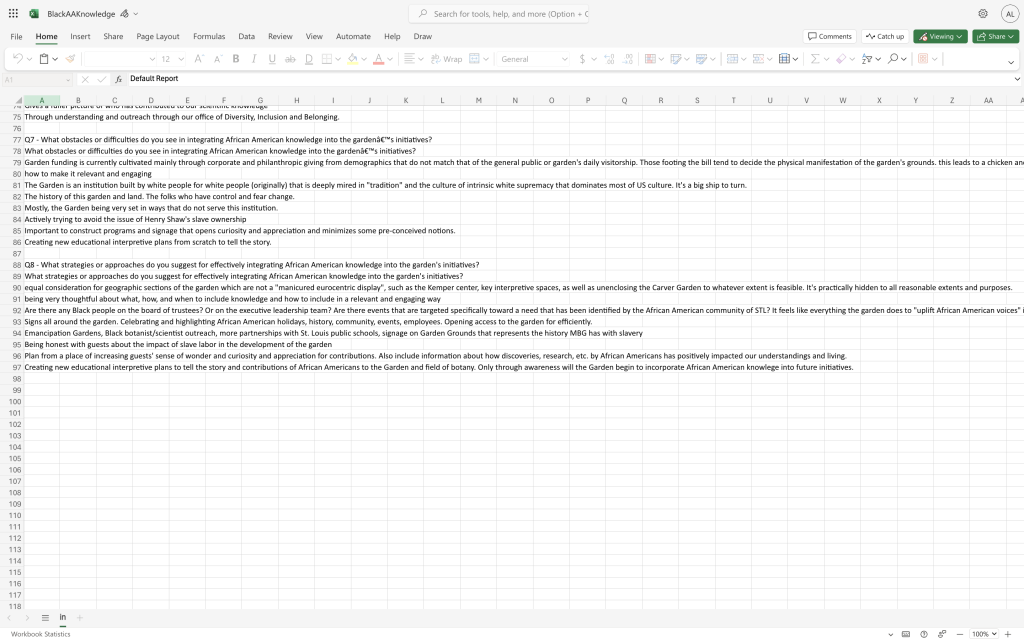
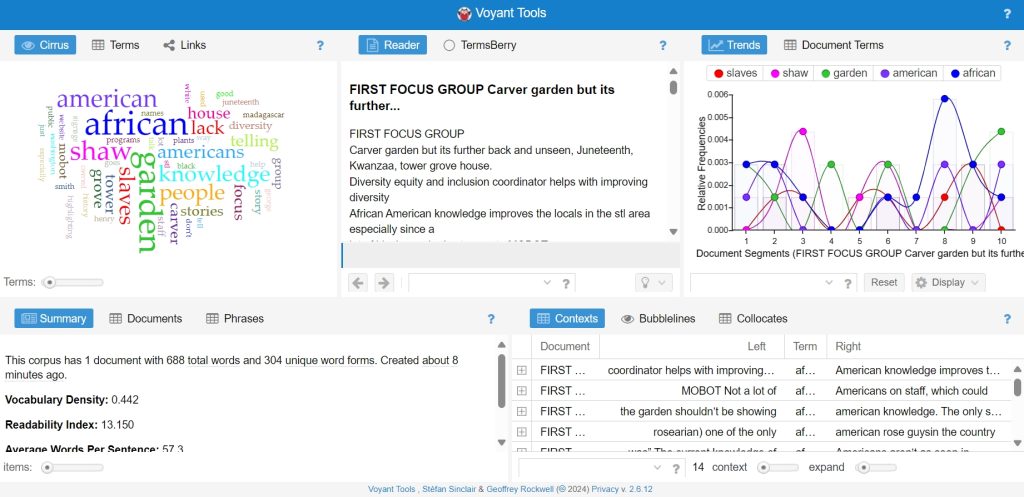
DATA CLEANING/ VISUALIZATION
“Data cleaning is the process of preparing data for analysis by removing or modifying data that is incorrect, incomplete, irrelevant, duplicated, or improperly formatted” (What Is Data Cleaning?, n.d.). To ensure that there were no flaws in our data, we went through and transcribed our interviews, then cross referenced this with the notes and survey responses. This was then inserted into a website called Voyant. Voyant allows files of words to be inserted, then this information is transformed into a pretty photo based on most used words.
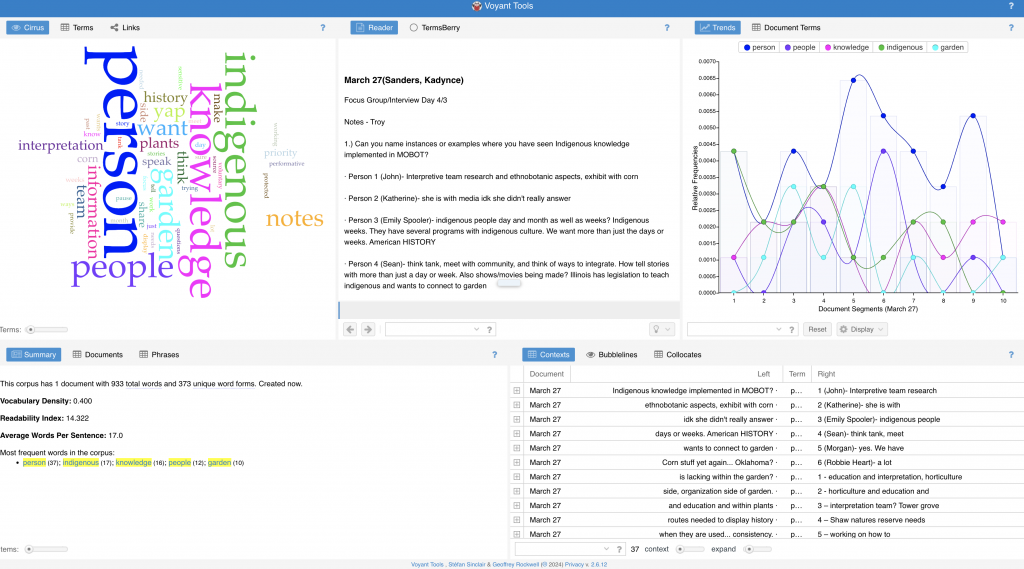
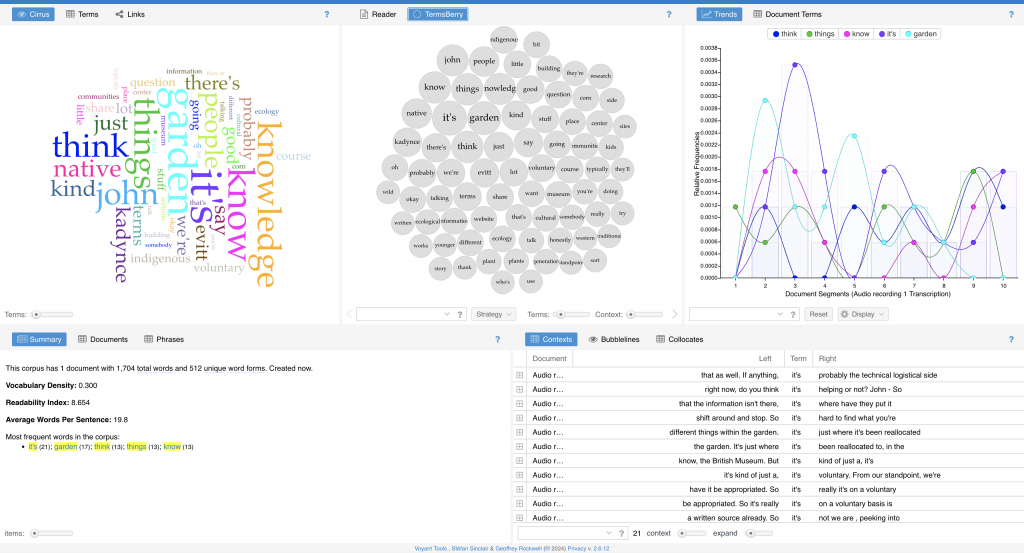
Resources
“What Is Data Cleaning?” Sisense, https://www.sisense.com/glossary/data-cleaning/. Accessed 12 Apr. 2024.